Evolving our static site architecture
![]() Chris Lunsford, AVP, Engineering
Chris Lunsford, AVP, Engineering
Where we started
Approximately six years ago, all of our services were hosted on Windows virtual machines in a data center with Microsoft’s Internet Information Services (IIS) and Apache. Deployments were performed manually by operations engineers and involved copying files received from developers to multiple VMs. When I joined SageSure in 2015, the DevOps team was already working on a project to dockerize all services and automate the deployments. After many months, and a few iterations on the architecture, we ended up with a more modern setup: dockerized services running on linux hosts deployed using automation from Jenkins.
This setup provided us a number of benefits:
- Deployments were automated, reducing time and errors associated with deployment.
- Build artifacts were immutable and generated with each release. Every commit to a releasable branch generated a docker image that could be deployed to any environment for testing.
- Scaling was easy. Instead of provisioning a new vm, we just needed to click a ’+’ button in Rancher, our Docker orchestration UI.
And this worked great for us. During this time, we were also migrating our services from the data center into AWS. The new dockerized setup made the move a lot easier.
Lingering pain points
But as the years have gone by, even as we enjoyed the benefits of our new architecture, we noticed a few weaknesses, particularly for our websites. Our routing layer relied on polling internal DNS to resolve the container IPs. As a result, every deployment had a small window (a few seconds, usually) where requests could fail if the old containers were destroyed before the proxy found the new containers.
Additionally, our frontend teams asked for the ability to preview a build for each feature branch before merging into the mainline. Thanks to our Docker architecture, we were able to add this functionality pretty easily by deploying the dockerized build and leveraging wildcard subdomains in DNS. However, this meant that we were now running dozens of copies of our frontend apps at the same time in our integration environment. Even with reduced memory reservations, we frequently ran out of capacity and had to scale up the cluster, or manually review and delete a large number of stale feature branch builds.
Lastly, running the websites within our own Docker infrastructure and behind our own proxies meant that any downtime or CPU contention in the cluster had a very visible impact to our users. Also, we weren’t doing anything explicit to manage the caching of website assets, so we would often have to instruct users to clear their browser cache if they were having issues after a deployment.
So it was time to evolve our architecture once again.
Implementing a static site architecture
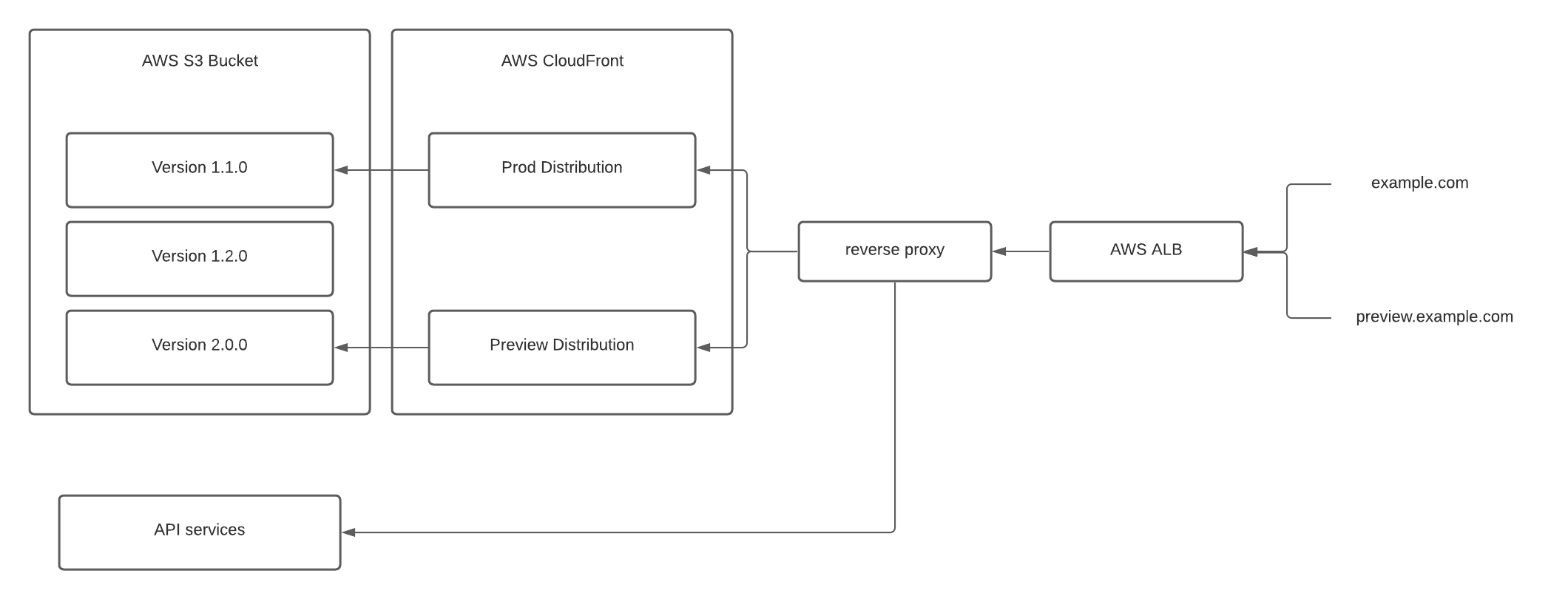
Our new architecture is based on AWS’s whitepaper for hosting static websites in AWS
In summary, the architecture consists of:
- An AWS S3 bucket to hold variations of the website (to support blue/green and preview deployments)
- AWS CloudFront distributions to serve as a CDN and cache-management solution
- AWS Application Load Balancer (ALB) to serve traffic to CDN or API
- AWS Web Application Firewall (WAF) to provide Geo/IP security restrictions to the CloudFront content
- A lightweight reverse proxy for API routes
Routing requests to the APIs
One of the key factors to consider in the new design was how we would route requests made by the website to a backend API. For all of our websites, the backend APIs were paths on the website domain (e.g. https://app.example.com/api) instead of on a dedicated API subdomain (e.g. https://api.example.com). Changing this would have ballooned the scope of the project, so we were left with handling the routes on the same domain. In practice, that means a request to the website domain could be intended for a backend or for the website itself, depending on the path. We used a lightweight reverse proxy to direct API-bound traffic to the appropriate backend service and route all remaining traffic to the webserver.
Moving forward, we had a few options for how we would split traffic between the CDN (taking over the job of serving the website assets) and the API backends:
- Put our reverse proxy inline, in front of the CDN. This would mean our proxy instance and docker infrastructure are still in the data path, but requires the least amount of change.
- Split traffic at the ALB layer using path-based routing. Ideally, we could collapse all backend routes to a common /api/ base to ease the routing configuration.
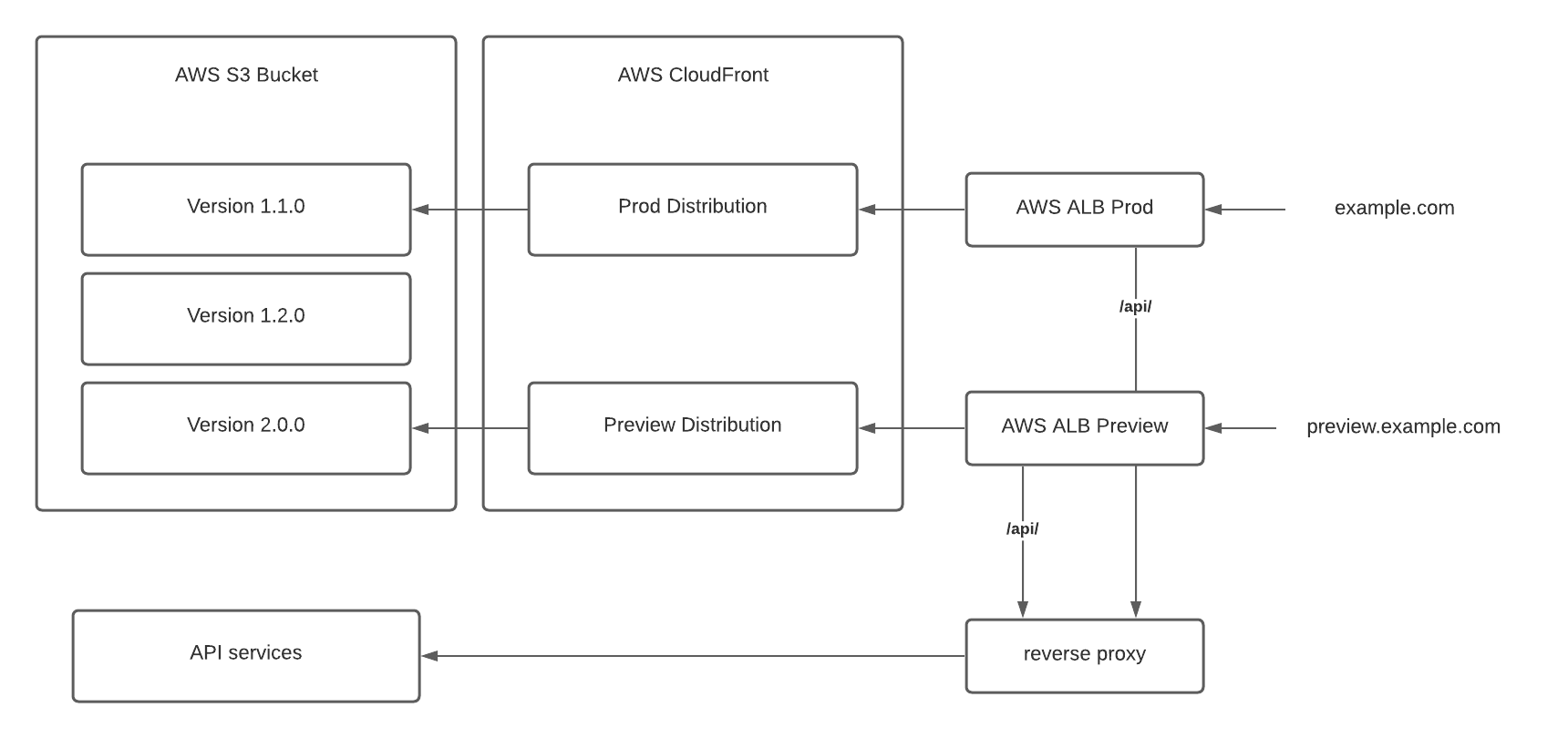
In the end, we decided to think of these as phases instead of competing options. We were able to deploy the first option quickly with minimal changes by leaving the API routing untouched. Once our websites are all migrated, we plan to implement option 2 and update the API routing to remove our proxy as a dependency of accessing the website.
Deploy process
The updated deployment process now works as follows:
- For each deployable build, the pipeline job compiles the static site and saves the bundle as an artifact.
- The bundle is synced to the environment s3 bucket under a versioned folder.
- For stage preview environments, the reverse proxy will take care of routing to the correct folder based on subdomain (No CDN is used for stage previews).
- For production preview, a post-deployment script will update the preview CloudFront origin to point at the new folder and perform cache invalidation, as required.
- Once the prod preview has been accepted, a second job will be used to update the production CloudFront origin to the new folder and perform cache invalidation, as required.
Notes:
- The active distribution files are never directly modified during deployment. This keeps each build immutable and available as a target for fast rollback.
- An alternative would be to use stable CloudFront origins (in blue/green style) and use either:
- DNS to switch between the active distribution. This, however, would subject users to DNS propagation delays.
- Weighted routing to use a single DNS entry against a blue/green CloudFront distribution. This would require maintaining blue-green state in the deployment script and preview routing to ensure the correct version is updated and enabled.
Conclusion
We migrated a major internal website to this new architecture late last year and it has been running in production without issues for the past 9 months. Our internal team has enjoyed the fast updates, the flexibility to deploy more often without user impact, and the increased number of available preview environments. We’re in the process of migrating our public websites to the new architecture so those teams can enjoy the same benefits.