Our path to CICD
![]() Shaun Abram, Vice President, Head of Engineering
Shaun Abram, Vice President, Head of Engineering
At SageSure, we are undertaking an initiative to migrate our projects to a full CICD pipeline. After code is merged to a main branch, it will run through a set of fully automated tests and, if all pass, be deployed to production. Automatically and quickly.
Our CICD goal: All Merge Requests should be capable of being released in less than 60 minutes.
This post is about why we want to move to CICD, the challenges we need to overcome, and how we will know we’re succeeding.
Current state
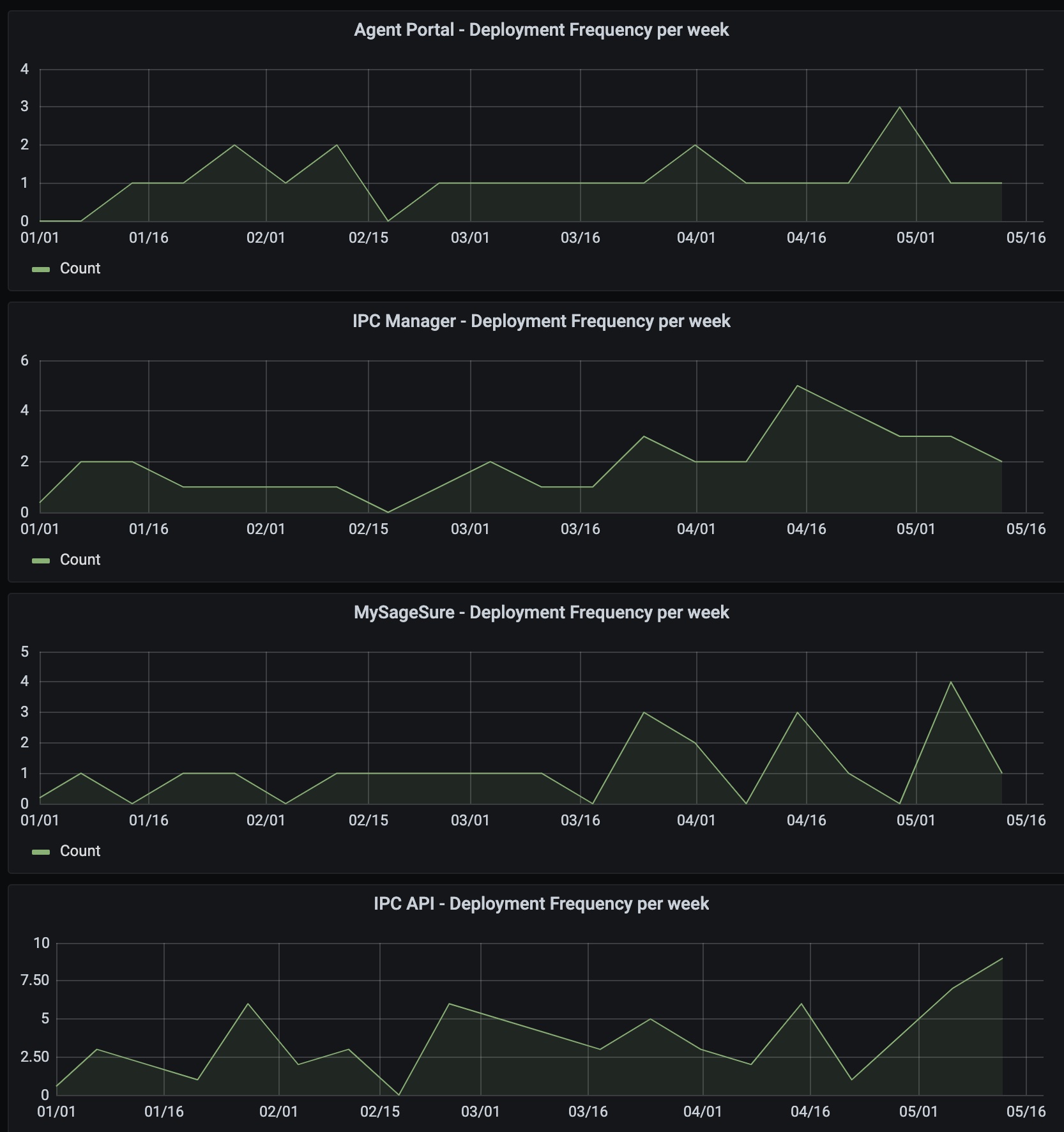
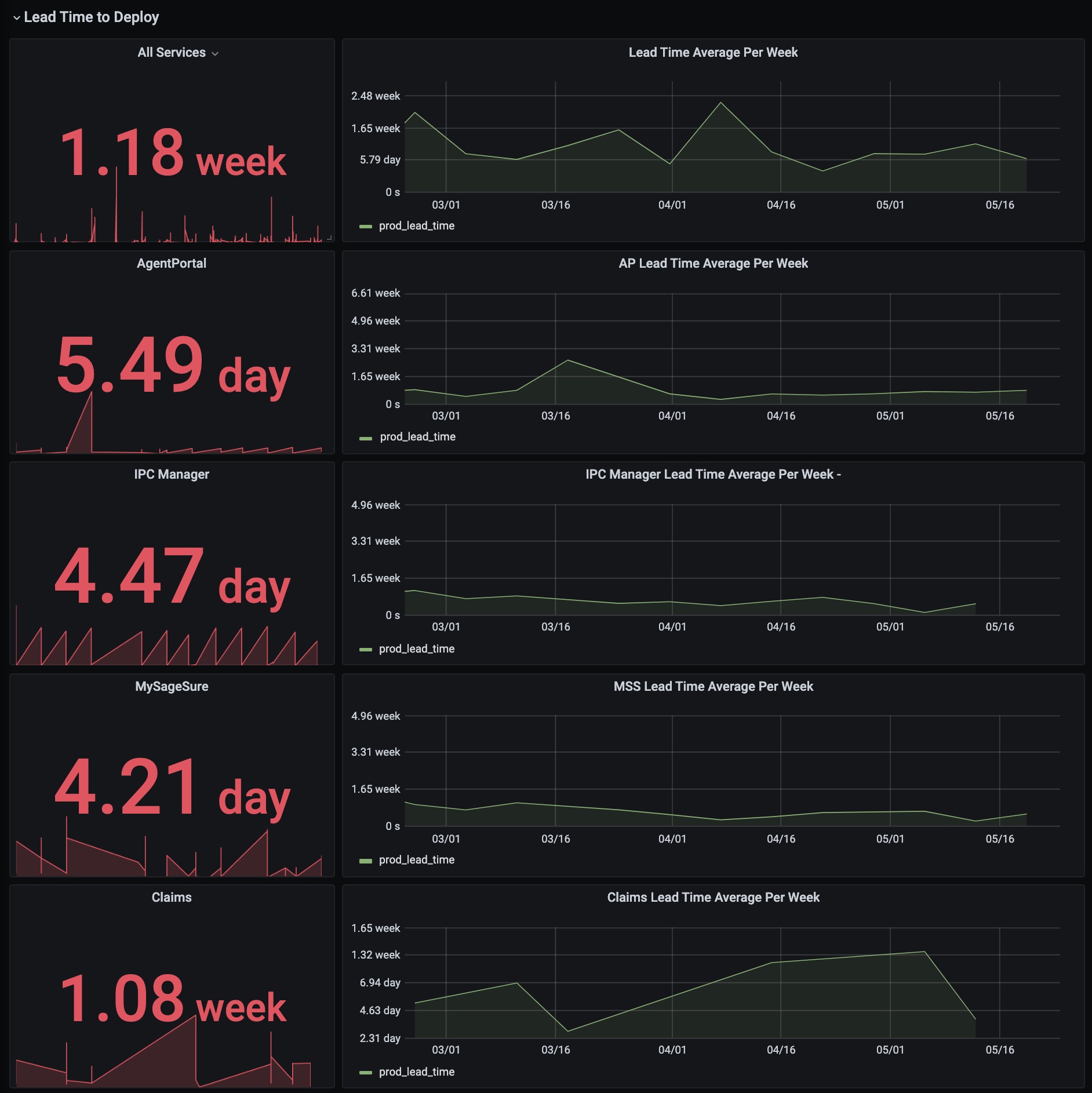
Currently we deploy to production about once a week for most projects. More frequently for our backend services, less frequently for our frontend apps. Our deployment frequency and lead time metrics both reflect this:
Why move to CICD?
There are 3 main reasons for us switching to CICD:
- Faster feedback
- Reduce the cost and risk of release
- Create a better place to work!
Faster feedback
Are we we delivering the right thing to our customers? In his 2012 Continuous Delivery talk, Jez Humble pointed to a study by the Standish Group that looked at the features used in applications, which found that
- 20% of features are often used
- 30% of features get used sometimes or infrequently
- 50% of features are hardly ever or never used

Half of the features that get developed being rarely ever used is a shocking statistic. Writing software that our customers don’t even want or use is a huge waste.
How do we reduce that waste? Lean principles suggest that we figure out how to build the smallest thing that would allow us to validate a hypothesis, and optimize for a build-measure-learn feedback loop. Listen, hypothesize, build, get feedback, iterate and repeat.
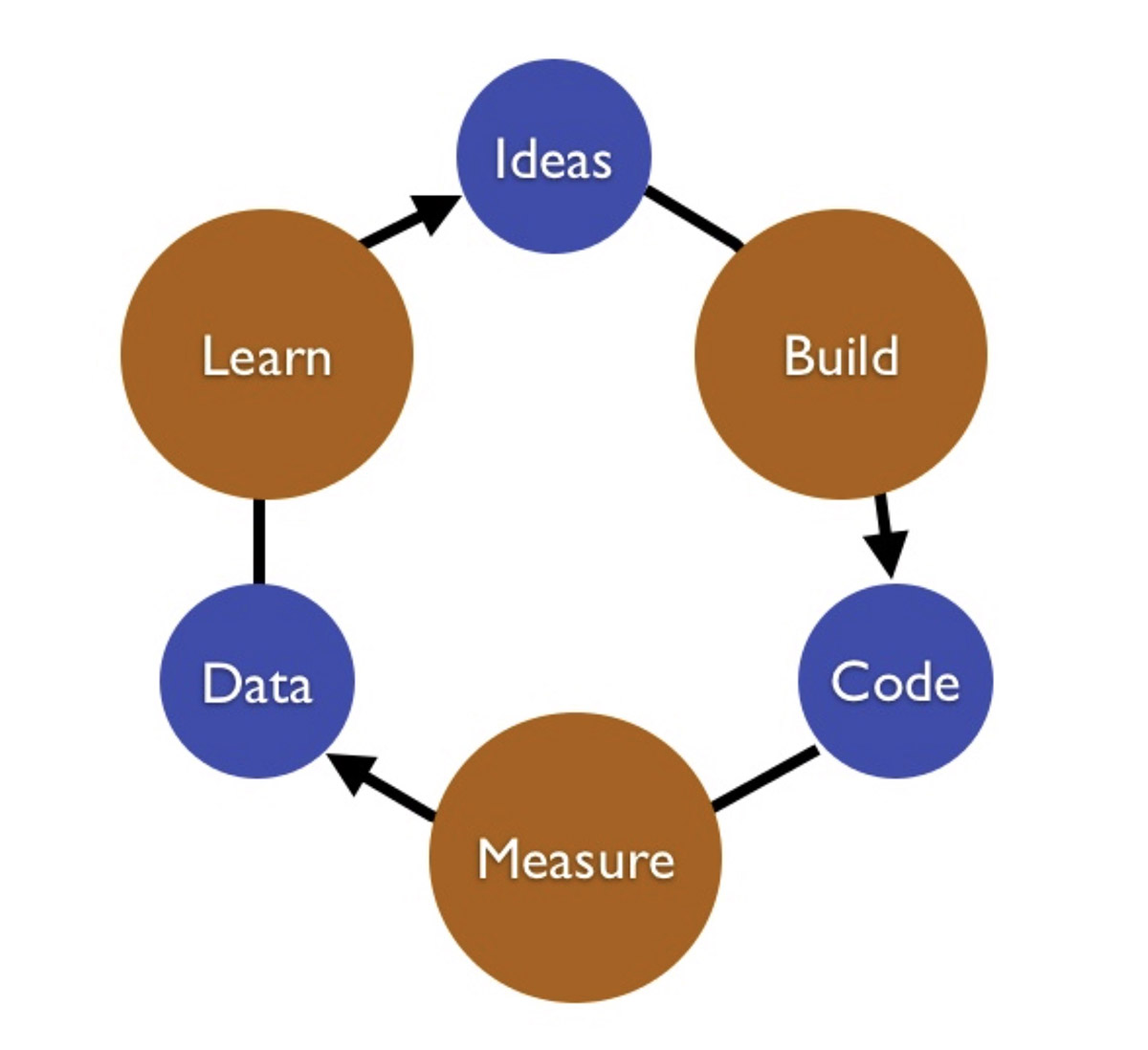
We want to optimize our software delivery process for time around this loop. And Lead Time is a key component of this cycle.
If you are not familiar with Lead Time, the Accelerate book defines Lead Time as:
“the time it takes to go from code committed to code successfully running in production.”
and states that:
“shorter product delivery lead times are better since they enable faster feedback on what we are building and allow us to course correct more rapidly.”
That is the first reason to move to CICD: to speed up our feedback loop and gain confidence, through quick iteration and experimentation, that we are in fact building the right thing.
Reducing the cost and risk of release
The cost
The problem with our current weekly deployments is that the cadence incurs very significant cost. I have previously written on my personal blog about the cost of slow lead times. On a team of 10 engineers, the costs associated with a one week lead time could be the approximate equivalent of more than 3 engineers, or $400,000 per year. That is a huge cost.
By decreasing the time it takes us to generate revenue from our new features, reducing the costs of necessary work such as coordinating and manual releases, and by reducing work in progress and context switching, we expect to significantly reduce our cost to release.
The risk
The bigger a release, the more changes being released at once. That means there are more chances of something failing, and when something does fail, it’s harder it is to know which change caused the problem and so it tales longer to triage the problem.
With CICD, each release is smaller. When something goes wrong, it is much easier to understand what caused. And of course having a CICD pipeline means you should be able to roll out a fix much faster too.
Creating a better place to work!
The last but by no means least reason for us to move to CICD is for our team.
Right now, some of our releases need to be done outside of working hours (typically after 8pm EST), and require the team to stay late. By moving to a CICD model, we can release anytime, including during working hours, and let the team go home at a reasonable hour. Enabling no-downtime releases is something we can do without moving to full CICD, but it is one of the many improvements that we are doing under the CICD umbrella.
And engineers want to work in a CICD environment. They want to see their changes have an impact quickly. They want to get the feedback of running their code in production. They want to work somewhere where they are working on interesting problems rather than repeatedly running the same manual processes.
Our path to CICD
In the excellent Continuous Delivery book, they talk about some of the practices and principles of continuous delivery, including developing a culture of continuous improvement, building quality in, automating where you can, and working in small batches. We are striving for all those things in SageSure, with more work to do in some of the areas than others.
But there are also specific technical challenges we face too. We talked earlier about the need to enable anytime deployments that do not impact customers. For us, this specifically includes migrating to CloudFront for our frontend services, and migrating to Kubernetes (from Rancher) for our backend services. Our Director of Engineering, Chris Lunsford, recently wrote about our Static-Site Architecture here.
We also need an increased focus on our tests. In a CICD world, a passing build should signal readiness for production. In addition to using automated test suites, we have also allowed our release candidates to “bake” in a stage environment, allowing internal users, tests and services to interact and (hopefully) smoke out any issues with a release. This can be an expensive and time consuming approach and we want to be faster and more consistent. Going forward, we want better automated test coverage and less manual. We need comprehensive unit, integration tests and browser based tests. We also in particular need to step up our API tests e.g., using Postman.
And with good test coverage in place, we need to make sure that we are running all the tests we can in production, for post deployment validation.
Finally, after deployment, we need better monitoring, observability and alerting. What does success of a new feature look like and are there specific metrics we can monitor for? Can we automatically detect unhealthy for a new feature, and automatically rollback? Can we optimize for Mean Time To Recover?
All of these are challenging tasks, but we are already making incremental improvements, and we don’t need to solve them all before moving to CICD. While better test coverage is a good way to reduce risk with CICD, more frequent releases themselves also reduce risk. Baby steps. Improve. Iterate.
How will we know if we’re succeeding?
One of the books we love at SageSure is Accelerate. We covered it in one of our bookclubs and we refer to it frequently. One of the reasons we like the book so much is that it brought a huge amount of data, rigor & scientific analysis to the table. The authors found a way to define & measure the performance of software teams, using these 4 metrics:
Throughput metrics
- Lead time
- Release Frequency
Stability metrics:
- Time to restore service (aka MTTR)
- Change Failure rate
As well as finding a way to measure performance, they found a way to predict it. Specifically, they found that the practices of Continuous Delivery predict the high performance of software teams. And what’s more, they found that high performers have practices & principles that allow them to achieve both higher throughput and stability.
For us in SageSure engineering, these are the metrics we are using as a guide in our migration to CICD.
We think about the the throughput metrics a lot and aiming for smaller batch sizes in the form of lower lead time and high release frequency.
And it is the stability metrics that we use as our guard rails along the way. If move to CICD, and we see an increase in our change failure rate, we are doing something wrong. And for each failed release, if it is taking longer to restore than what we are currently doing, we are again doing something wrong. In either case, we would need to step back and take stock. Gathering these metrics in advance has been very useful, and going into this transformation, we know:
- Where we’re starting from in terms of deploy frequency and lead times
- Where we want to go to: commit to production in an hour
- The metrics that show us if we’re breaking too many things along the way (MTTR and Change Failure rate)
So, to answer our initial question, how will we know if we’re succeeding with CICD? We will know when our metrics tell us. When we have improved throughput metrics in terms of lower lead time and increased release frequency, while not negatively impacting our stability metrics. Indeed it would be great to see our time to restore service (MTTR) and change Failure rate actually improve.
But more importantly, we will also see more and faster experimentation and iteration on features that our customers actually want and use.
Timelines
We are already making good progress and expect to have our first service on a CICD model in a few weeks, with the aim to have a significant number of services and UI apps on CICD by year end.
Will we migrate all projects to CICD? We haven’t decided yet. Instead, we plan to role out incrementally, review the benefits (and costs) and decide then.
We will be sure to create another post detailing or successes and failings as soon as we have meaningful progress to report.
In the meantime, if you are interested in joining us on our journey, please check out our openings and don’t hesitate to reach out.